Krista Ehinger*, Barbara Hidalgo-Sotelo*, Antonio Torralba, Aude Oliva
Visual Cognition , Vol. 17, 945-978.
First Published online: 25 June 2009.
|
|
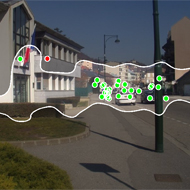
Modeling search for people in 900 scenes
Krista Ehinger*, Barbara Hidalgo-Sotelo*, Antonio Torralba, Aude Oliva Visual Cognition , Vol. 17, 945-978. First Published online: 25 June 2009. |
This code requires the matlabPyrTools steerable pyramid toolbox by Eero Simoncelli:
http://www.cns.nyu.edu/~lcv/software.php
Retraining the scene context model uses the labelMe toolbox and dataset:
http://labelme.csail.mit.edu/

|
Data set: Image stimuli Data set: Eye data Data set: Context oracle maps |
|
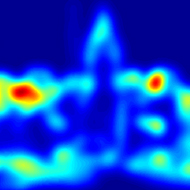
Pre-generated maps: Target features Maps Saliency Maps |