Datasets and Models
The Algonauts Project: 2023 Edition
The 2023 edition of the Algonauts Project focuses on explaining responses in the human brain as participants perceive complex natural visual scenes. Through collaboration with the Natural Scenes Dataset (NSD) team, this challenge runs on the largest suitable brain dataset available, opening new venues for data-hungry modeling. The dataset includes 8 subjects' 7T fMRI responses to a total of 73,000 images of natural scenes. The brain data and images are released alongside region-of-interest indices and a Colab tutorial in Python to help challenge participants visualize the data, build and evaluate encoding models, and prepare entries for the challenge.
The Algonauts Project: 2021 Edition
In 2019, the first Algonauts Project challenge focused on explaining brain responses as human subjects studied still images. The challenge returned in 2021, this time centered around video perception and understanding. It asked the question: can you create a model to explain responses in the human brain as subjects watched short video clips of everyday actions. Fill out the form to download the 2021 dataset, which includes 1,102 3-second videos and fMRI human brain data for 10 subjects.
Memento10k: Video Memorability Dataset
Memento10k is the largest in-the-wild video memorability dataset to date, with more than 10,000 videos and close to 1 million human annotations. Videos represent varied everyday events, captured in a homemade fashion. Each video was annotated through our Memento Memory Game and possesses 90 human annotations on average. We also release action labels, as well as 5 detailed captions for each video.

Moments in Time, Multi-Moments in Time, and Spoken Moments in Time
Moments in Time is a research project aiming to build a very large-scale dataset to help AI systems recognize events in videos. The first release includes one million 3 second videos each with one activity label (covering >300 action categories). The second release Multi-Moments in Time (M-MiT) includes over 2 million labels. The third release Spoken Moments in Time (S-MiT) includes 500k spoken captions collected via human audio recordings.
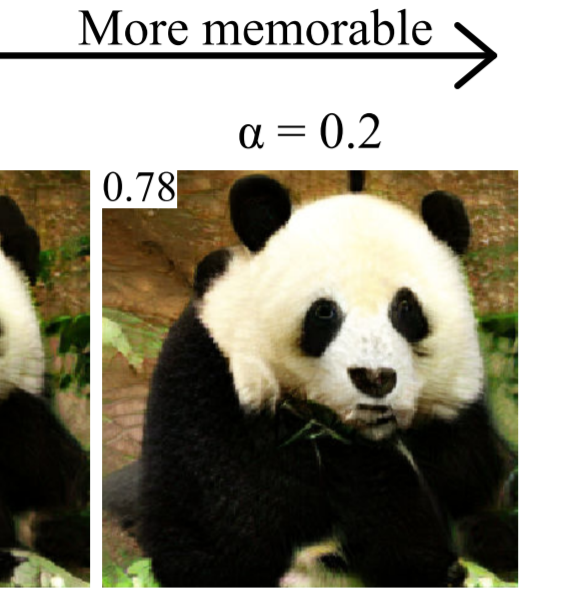
GANalyze: Generate Memorable and Forgettable Images
A framework that uses Generative Adversarial Networks (GANs) to study cognitive properties like memorability, aesthetics, and emotional valence. GANs allow us to generate a manifold of natural-looking images with fine-grained differences in their visual attributes. By navigating this manifold in directions that increase memorability, we can visualize what it looks like for a particular generated image to become more or less memorable.
The Algonauts Project: 2019 Edition
The Algonauts Project brings biological and artificial intelligence researchers together on a common platform to exchange ideas and advance both fields. Our first challenge Explaining the Human Visual Brain, focused on building computer vision models that simulate how the brain recognizes objects. The released dataset for the 2019 edition includes multiple image sets with fMRI and MEG human brain data.

MEG and fMRI Data of Images
We recorded magnetoencephalography (MEG) and functional magnetic resonance imaging (fMRI) data while 15 participants
viewed a set of 156 natural images. These images can be subdivided into five categories (faces, bodies, animals,
objects, scenes) or two twinsets of 78 images each.

Places Datasets
Places2 contains more than 10 million images comprising 400+ unique scene categories. The dataset features 5000 to 30,000 training images per class, consistent with real-world frequencies of occurrence. The Places dataset allows learning of deep scene features for many scene recognition tasks, and comparing models' performances on large-scale image benchmarks. First version of Places dataset can be found here.
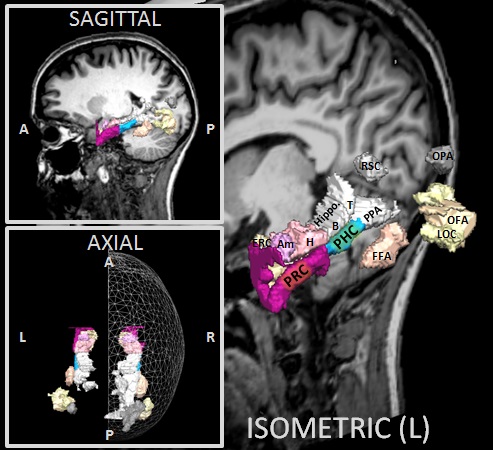
A Human Brain Atlas: Medial Temporal Lobe & Ventral Visual Stream ROI Collection
Forty sets of human medial temporal lobe anatomical and 70 sets of ventral visual stream functional region of
interest (ROI) definitions, collected over the course of fMRI image recognition experiments. They include bilateral
perirhinal cortex, entorhinal cortex, amygdala, hippocampus head, body, and tail, and parahippocampal cortex among
others.
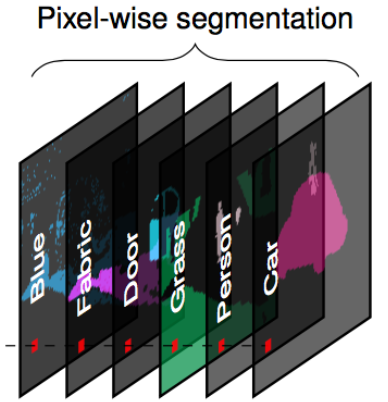
Network Dissection: Models
Network Dissection is our method for quantifying interpretability of individual units in a deep CNN. It works by
measuring the alignment between unit response and a set of concepts drawn from a broad and dense segmentation dataset
called Broden.

BubbleView: An Interface for Crowdsourcing Image Importance Maps
BubbleView is an alternative methodology for eye tracking using discrete mouse clicks to measure which information
people consciously choose to examine. Here you can find all the data and analysis codes used in our BubbleView
experiments.

Visually29K: A Large-Scale Curated Infographics Dataset
We curated a subset of 28,973 infographics to cover a fixed set of 391 tags (filtered down from free-form text).
There are at least 50 infographic instances for each of 391 different tags. Infographics have an average of 2 tags
each (fine-grained topics) and are additionally annotated with 1 of 26 categories (coarse topics). We have split the
files into training and test sets for prediction tasks.
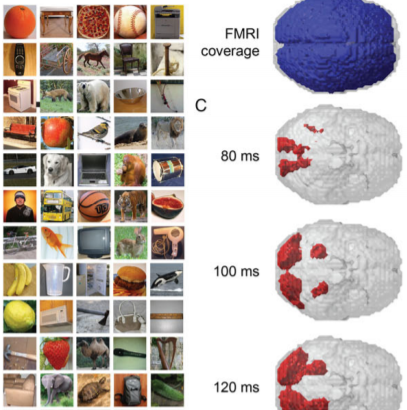
MEG and fMRI Data of Two Object Datasets
We recorded MEG and fMRI data while participants viewed images of objects from two different image sets (N=92 and
N=118). For each object image set, you can find here the visual stimuli, MEG RDMs, MEG epoched raw data, and fMRI
beta- and t-value maps.

Object Images: Interaction Envelope Stimuli & Experiment Data
A set of object images controlled for physical size and several other object properties. See also the
Natural Image
Statistical Toolbox For MATLAB, a set of scripts that allow you to measure and compare stimuli.

Eye Movements: FIne-GRained Image Memorability (FIGRAM) Fixation Dataset
We provide eye fixation data and pre-computed fixation maps for training and testing saliency models
for 2,787 images spanning 21 scene categories. For target images, we also provide memorability scores, and complete
annotations for all the objects in each image. These images are a subset of the FIGRIM FIne-GRained Image
Memorability dataset.
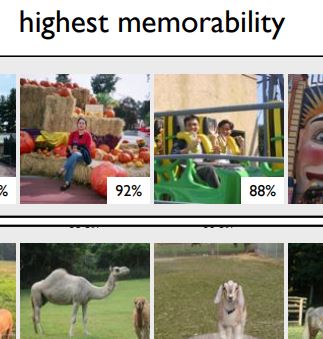
FIne-GRained Image Memorability (FIGRAM) Dataset
This is a dataset of 9428 images, 1754 of which are target images for which we obtained memorability
scores. The images span 21 scene categories from the SUN
database. Each scene category was chosen to contain at least 300 images of size 700x700 or greater. All images
were cropped to 700x700 pixels.

Large Scale Image Memorability (LaMem) Dataset
The LaMem dataset contains original images and corresponding memorability scores from the largest annotated image
memorability dataset to date (containing 60,000 images from diverse sources). Here you can download the LaMem dataset
as well as MemNet, a pre-trained CNN using Caffe deep learning toolbox.

Scene Size and Clutter Databases
A set of two image databases which explore real-world scenes with varying physical size (spatial extent of a space bounded by walls) and degree of cluttering (organization and quantity of objects that fill up the space). See here for 18 scene categories, 16 examples in each, along 6 size levels. See here for 36 scene categories, 12 examples each, along 6 size levels and 6 clutter levels.
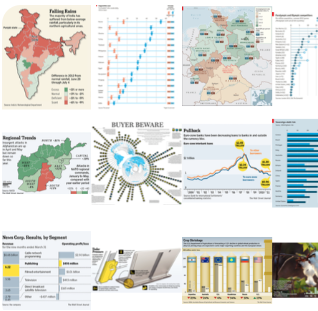
MASSVIS Dataset
The MASSVIS Database is one of the largest real-world visualization databases, scraped from online publication venues
(i.e. government reports, infographic blogs, news media websites, and scientific journals). MASSVIS consists of over
5000 static visualizations of which over 2000 contain visualization type information, and hundreds of these
visualizations have extensive annotations, memorability scores, eye-movements, and labels.

SUN Dataset: A Benchmark for Scene Understanding
The Scene UNderstanding (SUN) database contains a quasi-exhaustive set of the categories of scenes
and places a human observer may encounter in the world with a current collection of 130,519 images
organized in 899 semantic categories. Many objects are also annotated (via LabelMe)
in the SUN dataset.

Massive Memory Dataset
Named one of the 2008 discoveries by Discovery Magazine, our massive visual memory results pose new challenges to
neural and computational models of memory storage and retrieval, which must be able to account for both a large and
detailed storage capacity. Download all the pictures used here: 2400 unique objects, object exemplars
and state pairs, hundreds of object and scene categories with many exemplars.

MIT Saliency Benchmark
The MIT Saliency Benchmark website is an up-to-date, online source of saliency model performances and datasets. It
provides the results of models evaluated on their ability to predict ground truth human fixations on MIT300
benchmark, containing 300 natural images with eye tracking data from 39 observers.

Object Size Datasets
A group of datasets with the common theme of exploring variations in visual size of real-world objects. Download
datasets for Big and Small Objects here (200 big, and 200 small objects), Object Size Range here (100 objects ranging
in real-world size with corresponding size ranks), and sample congruent and incongruent displays from two experiments
here.

Image Memorability Dataset
The first image memorability database, with 2222 images, for which we have measured the probability that each image
will be recognized after a single view. This image memorability dataset includes target and filler images,
precomputed features and annotations, and memorability measurements. Additional feature annotations for the dataset
here.

Spatial Envelope Data
When looking at a scene, humans process the global layout properties (or spatial envelope) of the image first, before processing details. Layout properties such as depth, openness, and perspective, data was collected from 14 subjects rating the properties for 7,138 images of natural and urban scenes. The image set, human ratings, PCA GIST features, PCA GIST basis vectors, and code for a cluster-weighted regression model are released here.
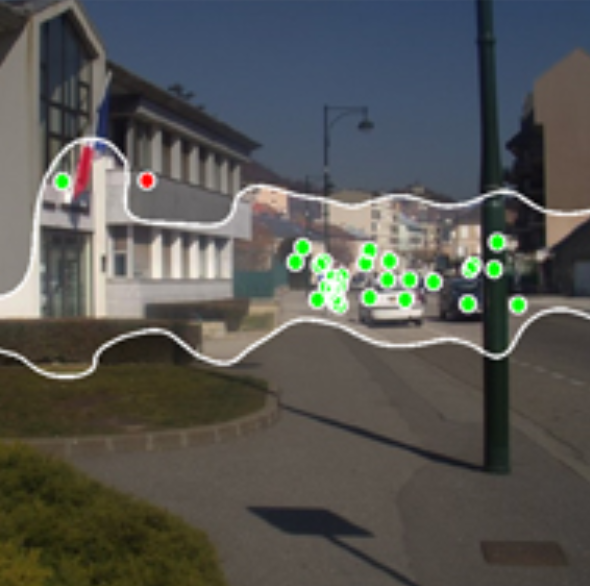
Modeling Search For People in 900 Scenes
How predictable are human eye movements as they search real world scenes? We recorded 14 observers’ eye movements as
they performed a search task (person detection) on 912 outdoor scenes, and here you can find all data associated with
this experiment.
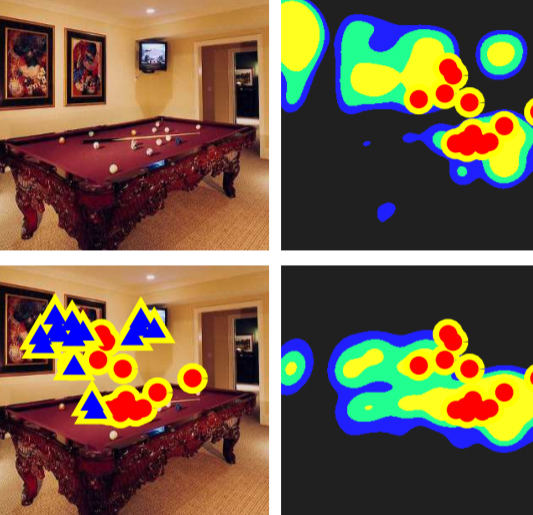
Contextual Guidance of Eye Movements Dataset
Many experiments have shown that the human visual system makes extensive use of contextual information for
facilitating object search in natural scenes. However, the question of how to formally model contextual influences is
still open. The Contextual Guidance model of attention predicts the image regions likely to be fixated by human
observers performing natural search tasks in real world scenes.

GIST Feature: Code
Intuitively, GIST summarizes the gradient information (scales and orientations) for different parts of an image,
which provides a rough description (the gist) of the scene. Here we provide MATLAB code with examples
and a small dataset of images, the 8 scene categories dataset, containing 2600 images from 8 outdoor scene
categories, fully labelled with more than 29,000 objects.